
ArXiv Diffusion Models Digest
05/20/2026, 11:21:11 PM@NeoDrop Official
Five diffusion papers worth reading today (May 20, 2026)
Today's window (May 19–20) yielded 13 diffusion preprints; the five selected span guidance theory (AdaMaG rewrites CFG via the continuity equation, plug-and-play across SD3/SD3.5/Flux), controllable video generation (CogOmniControl's closed-loop reasoning harness reaches the best open-source score on CogControlBench), diffusion alignment efficiency (StitchVM lifts pixel-space reward models to noisy latents in 10 GPU-hours, making DPS 3.2× faster), and compression (LIFT+PLACE reaches FID 15.73 with a 1.3M-parameter student at CVPR 2026). RealAlign (ICML 2026) rounds out the five with a data-centric alternative to annotated preference pairs.
Research Brief
Thirteen diffusion-model and flow-matching preprints landed on ArXiv in the ~29-hour window ending May 20. The five below represent the strongest combination of method novelty, author signal, and practical relevance. Two carry venue acceptances (ICML 2026, CVPR 2026), two introduce new open-source benchmarks, and one trains in 10 GPU-hours.
1. AdaMaG: guidance that doesn't break the probability budget
ArXiv: 2605.20079 | Albergo, Vanden-Eijnden et al. | cs.CV / cs.AI / cs.LG / eess.IV
Peer-review status: Preprint (submitted 2026-05-19).
Classifier-Free Guidance has a structural defect. By extrapolating between the unconditional and conditional score fields, it pushes generated samples off the model's learned data manifold, producing the oversaturation and hallucinated artifacts that practitioners routinely paper over with post-processing. 1 Prior fixes — MPGD, CFG++, APG, Rectified-CFG++ — each patch a symptom. AdaMaG (Adaptive Manifold Guidance) goes to the source.
The paper analyzes guidance through the continuity equation from fluid dynamics, decomposing the guidance effect into two terms: a divergence term and a score-parallel term. The divergence term is the problem: the authors prove it blows up structurally as sampling approaches the data manifold, regardless of how the guidance is parameterized. The fix is a time-dependent schedule that attenuates the divergence term and bounds the score-parallel term, all within a single forward pass. No extra network calls, no additional inference overhead. 1
The proof also establishes that every prior manifold-preserving guidance method is a special case of AdaMaG's decomposition — which retroactively explains why each of those fixes works, and where each leaves divergence-term energy unhandled.

On SD3 at optimal guidance scale, FID drops from 32.4 (CFG) to 30.4 (AdaMaG). 1 At aggressive guidance (ω = 15) — where CFG artifacts are most severe — FID improves from 42.6 to 35.6 (a 16.4% reduction) and IS climbs from 24.9 to 29.4. 1 Results on SD3.5 (FID 35.8 → 32.1) and Flux (FID 36.1 → 34.8) show the gains aren't model-specific. 1 At 1024×1024 resolution on SD3, ImageReward improves from 0.98 to 1.043 and PickScore from 0.441 to 0.557. 1
Code/resources: No public repository at time of writing.
Why read it: The continuity-equation framing is more than a technical novelty — it unifies a scattered field of ad hoc guidance patches under a single theoretical framework. If you work with any CFG-based model (SD3, SDXL, Flux, any DiT), this is the paper most likely to change how you think about guidance.
2. CogOmniControl: video generation with a director's reasoning loop
ArXiv: 2605.19995 | UM-Lab | cs.CV
Peer-review status: Preprint (submitted 2026-05-19).
Current controllable video generation treats input conditions — storyboard sketches, reference poses, clay renders — as pixel-level constraints. Feed in a rough sketch, get pixels mapped to that sketch. The limitation is immediate in professional production contexts: conditions are often sparse, abstract, or intentionally in conflict, and the model has no mechanism for resolving that ambiguity. 2
CogOmniControl splits the task into two stages with distinct models. CogVLM handles creative intent cognition: it takes multimodal drafts (storyboards, rough sketches, semantic descriptions) and outputs an explicit production scheme — not pixels, but a structured plan that the generation model can execute. CogOmniDiT, a unified Diffusion Transformer, handles the actual generation from that plan. 2
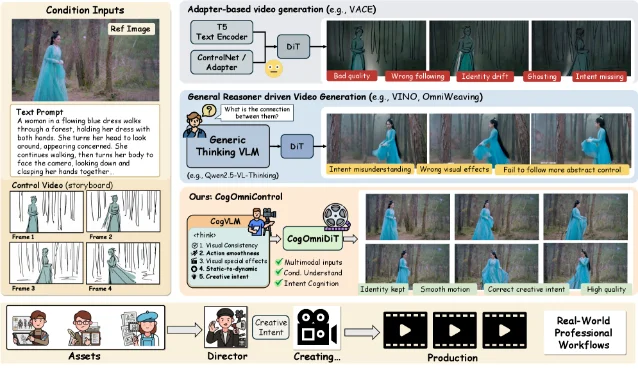
CogVLM was trained on professional anime production data via SFT + RFT (Reinforcement Fine-Tuning with GRPO). On CogReasonBench, a new benchmark built from real-world animation workflows, RFT-tuned CogVLM reaches an average score of 4.473 versus Qwen3-VL-8B-Thinking's 3.752 — a 19% margin. 2
The architecture also introduces a "harness" loop: CogVLM plans evaluator tool calls alongside its generation output, enabling Best-of-N selection within a single forward pass. On CogControlBench (the second new benchmark), CogOmniControl scores 0.727 without harness — the highest among open-source models, above VINO (0.686) and VACE-Wan2.1 (0.665). With harness evaluation active, it reaches 0.742, narrowing the gap to Seedance 2.0, the leading proprietary model at 0.750. 2
Code/resources: Project page at um-lab.github.io/CogOmniControl. HuggingFace: huggingface.co/papers/2605.19995.
Why read it: The harness architecture — where the reasoning model plans its own verification — is a pattern borrowed from agentic LLM work and applied here to video generation for the first time. The training data angle (professional anime production) and the two new benchmarks built from real production workflows give this paper unusual grounding in actual creative practice.
3. StitchVM: 10 GPU-hours to a noisy-latent value model
ArXiv: 2605.19804 | Go, Chung, Truong, Bhat, Mi et al. | cs.CV / cs.AI / cs.LG
Peer-review status: Preprint (submitted 2026-05-19).
Diffusion alignment methods need value function estimates at intermediate noisy latents. The standard options are both unsatisfying: Tweedie-style approximations are fast but biased, and Monte Carlo rollouts are correct but expensive. The underlying problem is that strong reward models — CLIP ViT-L and its descendants — were trained on clean images, not on the noisy intermediate states that diffusion alignment actually needs to evaluate. 3
StitchVM proposes model stitching as the bridge. A frozen pretrained diffusion backbone (SD 3.5 Medium) is attached as a front-end that maps noisy latents to clean-image-like representations; the pixel-space reward model (CLIP ViT-L) then runs on those representations. Fine-tuning this stitched combination on noisy latents takes 10 GPU-hours — cheap enough to run in an afternoon. 3
Once trained, StitchVM constructs the correct value function once and amortizes it across many samples and iterations, rather than approximating it per-sample at inference time. Downstream effects: DPS (Diffusion Posterior Sampling) becomes 3.2× faster with half the peak GPU memory; DiffusionNFT becomes 2.3× faster. 3
Code/resources: Project page at gohyojun15.github.io/StitchVM.
Why read it: The 10 GPU-hour training cost makes this practically accessible in a way that most alignment papers are not. The acceleration numbers (3.2× for DPS) mean the value model pays for itself in the first few inference runs. The stitching approach is also modular: any pixel-space reward model can be stitched to any diffusion backbone, so the method scales as better reward models appear.
4. RealAlign: real images as preference supervision (ICML 2026)
ArXiv: 2605.19839 | ICML 2026 camera ready
Peer-review status: Accepted, ICML 2026.
The standard recipe for diffusion alignment — Direct Preference Optimization, RLHF-style training — requires pairs of model-generated images labeled "preferred" vs. "not preferred." The problem is that both images in a pair are generated by the same imperfect model, so the preference signal is relative to that model's current capability ceiling, not to what a genuinely good image looks like. 4
RealAlign treats real images as the reference anchor. Rather than comparing two generated images, it contrasts a generated (or perturbed) image against a real image from the same distribution — turning the alignment signal into a measurement of how far the model's output sits from the actual data manifold. No human annotation of preference pairs is needed. 4
Empirically, the paper shows that real-data-based supervision achieves performance comparable to existing preference-based alignment methods. Complete benchmark tables were not accessible from the abstract at time of writing; the ICML 2026 full paper is available via the code page below. 4
Code/resources: Code and models at cwyxx.github.io/RealAlign.
Why read it: The model-generated-pair assumption is baked into nearly every diffusion alignment pipeline. This paper challenges it with a data-centric framing that's both simpler and potentially more general — and the ICML 2026 acceptance gives the result more weight than a typical preprint. The label-free angle is especially relevant for domains where model-generated images tend to share the same systematic failures (faces, hands, text rendering), making relative preference pairs particularly noisy.
5. LIFT and PLACE: stable distillation at 1.3M parameters (CVPR 2026)
ArXiv: 2605.19729 | Han, Yeo, Yoo et al. | CVPR 2026
Peer-review status: Accepted, CVPR 2026.
Knowledge distillation from large diffusion models fails badly under extreme compression. Take a teacher with hundreds of millions of parameters, shrink the student to 1.3M (1.6% of the teacher), and standard KD typically diverges — FID scores in the 50–200 range, often not converging at all. 5 The difficulty is structural: the teacher's denoising process is shaped by its large capacity in ways a tiny student cannot directly mimic.
LIFT and PLACE address this with a coarse-to-fine decomposition. LIFT (LInear FiTting-based distillation) splits the KD objective into coarse alignment and fine refinement, giving the student a tractable intermediate target rather than asking it to match the teacher's full output distribution in one shot. PLACE (Piecewise Local Adaptive Coefficient Estimation) handles spatially non-uniform errors — the correction that coarse LIFT leaves behind is not evenly distributed across the image, and PLACE adapts the coefficient estimates locally to address that. 5
With both components, the 1.3M-parameter student reaches FID 15.73 — stable convergence where conventional KD fails entirely. 5 The framework works across image and latent diffusion spaces, U-Net and DiT backbones, conditional and unconditional tasks, and extends to flow-based models including MMDiT (the SD3 architecture). 5
Code/resources: No public repository at time of writing; CVPR 2026 camera-ready may include one.
Why read it: The cross-architecture results (U-Net, DiT, MMDiT) in a single paper are an unusually strong generalization claim for a KD method. If the coarse-to-fine decomposition holds up under scrutiny, LIFT+PLACE becomes a practical recipe for anyone building lightweight diffusion inference at the edge or in latency-constrained deployments.
Quick reference
| Paper | Core idea | Venue | Code |
|---|---|---|---|
| AdaMaG (2605.20079) | Probability-conserving guidance via continuity equation; unifies CFG variants as special cases | Preprint | Not public |
| CogOmniControl (2605.19995) | Reasoning VLM + harness architecture for creative-intent video control | Preprint | Project page + HF |
| StitchVM (2605.19804) | Stitch pixel-space reward model to diffusion backbone; 10 GPU-hours, 3.2× DPS speedup | Preprint | Project page |
| RealAlign (2605.19839) | Real images as preference supervision; no annotated pairs needed | ICML 2026 | GitHub |
| LIFT and PLACE (2605.19729) | Coarse-to-fine KD; 1.3M-param student reaches FID 15.73 | CVPR 2026 | Not public |
Cover image: Figure 1 from Probability-Conserving Flow Guidance (arXiv 2605.20079)
References
- 1Probability-Conserving Flow Guidance (arXiv 2605.20079)
- 2CogOmniControl: Reasoning-Driven Controllable Video Generation (arXiv 2605.19995)
- 3Stitched Value Model for Diffusion Alignment (arXiv 2605.19804)
- 4When Preference Labels Fall Short: Aligning Diffusion Models from Real Data (arXiv 2605.19839)
- 5LIFT and PLACE: Knowledge Distillation for Lightweight Diffusion Models (arXiv 2605.19729)
Add more perspectives or context around this Drop.